Assay pipeline#
The assay preprocessing pipeline is applied after all samples were processed by the sample pipeline. The
AssayStorage centralizes the storage of data from all samples
At this point, descriptors from all features in the assay are computed and stored also.
The assay data flow enforces one main restriction: all sample data is read only. At first sight this restriction may seem excessive, but it will make sense once we consider the main goal of the assay workflow, which is to combine data from multiple samples to create the data matrix. Let’s start by reviewing how the data matrix is created as this will help us understand the rationale for the assay data flow.
A data matrix is an \(n \times m\) matrix where \(n\) and \(m\) are the number of samples and the
number of feature groups in the assay, respectively. A feature group is a collection
of features from multiple samples associated with the same chemical species. The
FeatureGroup model contains the combined information from all features
in the group. The matrix elements are indexed by a (sample id, feature group) pair and its value is
defined by the value of a feature descriptor that matches the matrix index.
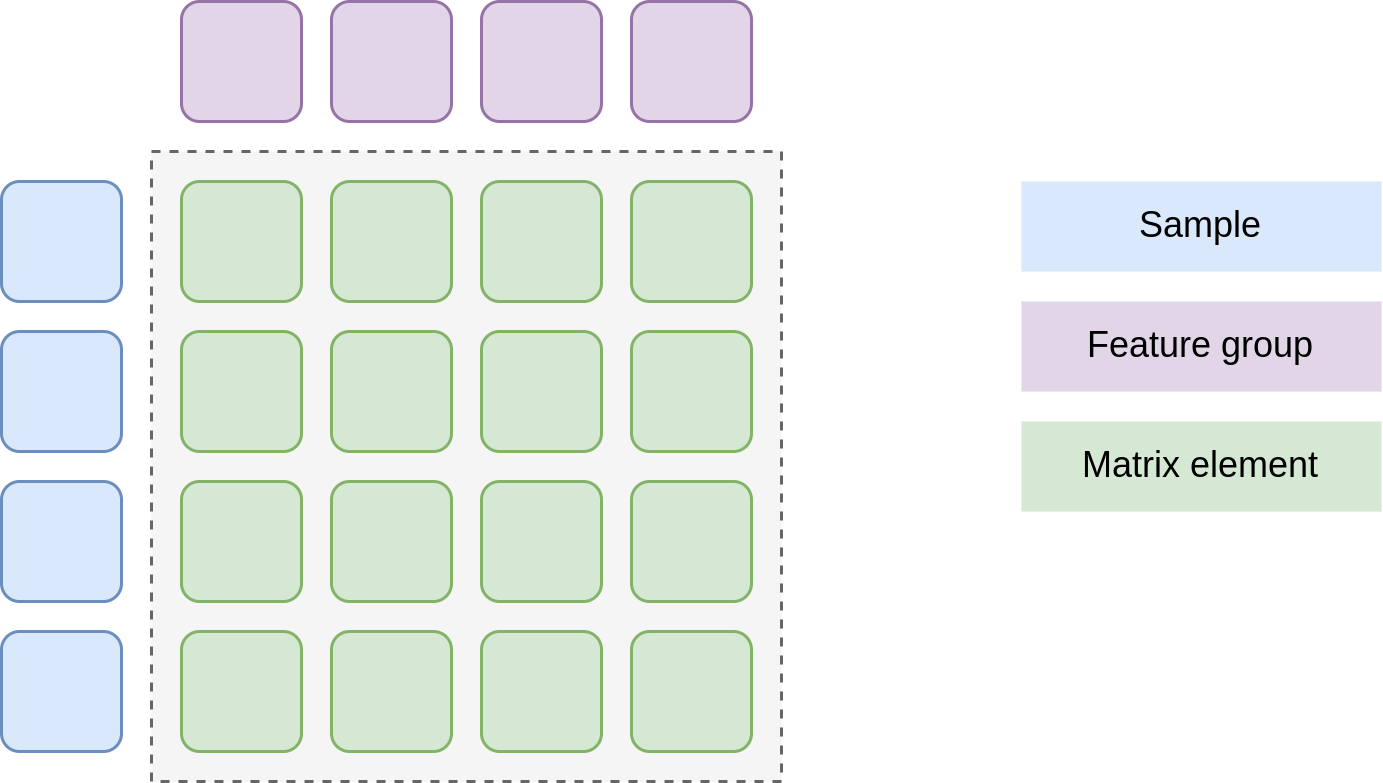
Structure of the data matrix.#
Building the data matrix involves the following steps:
Assign a
groupto all features in the assay. This involves applying a feature matching algorithm.Compute all feature groups. This process involves computing a consensus annotation and aggregated descriptors using all features in the group.
Compute matrix entries values for each (sample id, feature group) pair. This involves using a feature descriptor as the matrix value for the entry. Multiple features from the same sample may share the feature group. In this case, the matrix element contains the additive contribution from each feature. This approach allows to consider the case where multiple features from a sample need to be merged into a single feature.
Optionally, add matrix element values in cases where no feature matches their associated (sample id, feature group) pair (missing value imputation).
Note that steps 2 and 3 perform computations of feature group and matrix elements using information from
Feature models, so in this case no modification of sample data is required.
Step 4 computes matrix missing values using FeatureGroup and
Sample information. Again, it is not required to modify the sample data.
On the other hand, step 1 requires patching the group value, which
is set to -1 during the sample preprocessing stage.
To avoid modification of sample data, the concept of patches is introduced. Patches modify the
feature annotation or feature descriptor values of specific features without modifying data extracted
during the sample preprocessing stage. Patches are stored as separate entities and are applied to data
on the fly when requested from the assay storage. The following models are used in the assay pipeline:
DescriptorPatch, AnnotationPatch and
FillValue. The following operators compute and applies the patches
to the assay data: DescriptorPatcher,
AnnotationPatcher and
MissingImputer.
The following table enumerate the requirements for applying each one of the assay operators:
Operator |
Adducts annotated |
Isotopologue annotated |
Features matched |
Feature groups computed |
Missing imputed |
|---|---|---|---|---|---|
AnnotationPatcher |
No |
No |
No |
No |
No |
DescriptorPatcher |
No |
No |
No |
No |
No |
MissingImputer |
No |
No |
Yes |
Yes |
No |
The minimum requirement to create a data matrix is to perform feature matching. This
allows to create a DataMatrix, which will be used
in the Matrix pipeline.
As an example, let’s consider an assay pipeline for LC-MS data, which typically consists in peak alignment, find missing values and data matrix creation. Peak alignment usually consists in correcting peaks’ retention time and then match peaks from multiple samples based on m/z and Rt closeness. The retention time is a peak descriptor, so the first part of this pipeline is a feature patcher that computes a corrected retention time value for each peak in the assay. The second part, involves computing a feature group based on m/z and Rt values, i.e., an annotation patcher. The last step in this pipeline consists in finding missing values involve performing a targeted search for missed peaks on raw data. This is implemented using the missing imputer. The following diagram displays this example pipeline:

Example workflow for LC-MS data.#